Scraping the NFL Salary Cap Data with Python and R
The NFL Data
[SporTrac](http://www.sportrac.com] has a wonderful array of financial data on sports. A student going to work for the Seattle Seahawks wanted the NFL salary cap data and I also found data on the English Premier League there. Now I have a source to scrape the data from.
With a source in hand, the key tool is the SelectorGadget. SelectorGadget is a browser add-in for Chrome that allows us to select text and identify the css or xpath selector to scrape the data. With that, it becomes easy to identify what we need. I navgiated to the website in base_url and found the team names had links to the cap data. I will use those links first. Let’s build that.
library(rvest)
base_url <- "http://www.spotrac.com/nfl/"
read.base <- read_html(base_url)
team.URL <- read.base %>% html_nodes(".team-name") %>% html_attr('href')
team.URL## [1] "https://www.spotrac.com/nfl/arizona-cardinals/cap/"
## [2] "https://www.spotrac.com/nfl/atlanta-falcons/cap/"
## [3] "https://www.spotrac.com/nfl/baltimore-ravens/cap/"
## [4] "https://www.spotrac.com/nfl/buffalo-bills/cap/"
## [5] "https://www.spotrac.com/nfl/carolina-panthers/cap/"
## [6] "https://www.spotrac.com/nfl/chicago-bears/cap/"
## [7] "https://www.spotrac.com/nfl/cincinnati-bengals/cap/"
## [8] "https://www.spotrac.com/nfl/cleveland-browns/cap/"
## [9] "https://www.spotrac.com/nfl/dallas-cowboys/cap/"
## [10] "https://www.spotrac.com/nfl/denver-broncos/cap/"
## [11] "https://www.spotrac.com/nfl/detroit-lions/cap/"
## [12] "https://www.spotrac.com/nfl/green-bay-packers/cap/"
## [13] "https://www.spotrac.com/nfl/houston-texans/cap/"
## [14] "https://www.spotrac.com/nfl/indianapolis-colts/cap/"
## [15] "https://www.spotrac.com/nfl/jacksonville-jaguars/cap/"
## [16] "https://www.spotrac.com/nfl/kansas-city-chiefs/cap/"
## [17] "https://www.spotrac.com/nfl/las-vegas-raiders/cap/"
## [18] "https://www.spotrac.com/nfl/los-angeles-chargers/cap/"
## [19] "https://www.spotrac.com/nfl/los-angeles-rams/cap/"
## [20] "https://www.spotrac.com/nfl/miami-dolphins/cap/"
## [21] "https://www.spotrac.com/nfl/minnesota-vikings/cap/"
## [22] "https://www.spotrac.com/nfl/new-england-patriots/cap/"
## [23] "https://www.spotrac.com/nfl/new-orleans-saints/cap/"
## [24] "https://www.spotrac.com/nfl/new-york-giants/cap/"
## [25] "https://www.spotrac.com/nfl/new-york-jets/cap/"
## [26] "https://www.spotrac.com/nfl/philadelphia-eagles/cap/"
## [27] "https://www.spotrac.com/nfl/pittsburgh-steelers/cap/"
## [28] "https://www.spotrac.com/nfl/san-francisco-49ers/cap/"
## [29] "https://www.spotrac.com/nfl/seattle-seahawks/cap/"
## [30] "https://www.spotrac.com/nfl/tampa-bay-buccaneers/cap/"
## [31] "https://www.spotrac.com/nfl/tennessee-titans/cap/"
## [32] "https://www.spotrac.com/nfl/washington-football-team/cap/"# Clean up the URLs to get the team names by themselves.
team.names <- gsub("/cap/","", gsub(base_url, "", team.URL))With 32 team links to scrape, I can now scrape them.
Grabbing Team Tables
Now I need to explore those links. When I started this, I wanted to learn some Python along the way. I found the following Python code that worked for the task. For completeness, I leave it here.
import pandas as pd
import bs4
import re
import urllib2
#import requests
from urllib import urlopen
from bs4 import BeautifulSoup
base_url = "http://www.spotrac.com/nfl/"
def get_page(url):
page = urlopen(base_url)
soup = BeautifulSoup(page, 'lxml')
file = open("spotrac_urls.txt", 'w')
file.write(str(soup))
file.close()
def get_team_table(url):
page = urlopen(url)
soup = BeautifulSoup(page, 'lxml')
get_page(base_url)
with open("spotrac_urls.txt", 'r') as file:
for line in file:
line = line.strip()
from bs4 import BeautifulSoup
page = open("spotrac_urls.txt", 'r')
soup = BeautifulSoup(page, "lxml")
div = soup.find("div","subnav-posts")
links = div.find_all('a')
for link in links:
print(link.get('href'))
len(links)
def get_team_table(url):
page = urlopen(url)
soup = BeautifulSoup(page, 'lxml')
data_rows = [row for row in soup.find("table", "datatable").find_all("tr")]
return data_rows
# create an empty list
team_data = []
for link in links:
team_data.append(get_team_table(link.get('href')))
len(team_data)
#data_rows = [row for row in soup.find("td", "center").find_all("tr")]
table_data = []
#soup = BeautifulSoup(team_data[0], 'lxml')
#This needs to be a nested for loop because inner items of the list are BeautifulSoup Elements
for row in team_data:
for element in row:
#print(type(element))
if soup.find_all("td", attrs={"class":" right xs-hide "}) is not None:
table_data.append(element.get_text())
player_data = []
for row in table_data:
player_data.append(row.split("\n"))
#print(player_data)
len(player_data)
import pandas as pd
df = pd.DataFrame(player_data)
df = df.drop(14, 1)
df = df.drop(0, 1)
df = df.drop(1, 1)
df = df.drop(df.index[[0]])
df.set_index(1, inplace=True)
print(df.shape)
df.head()
players = []
for row in team_data[0]:
if row.get_text("tr") is not None:
players.append(row)
column_headers = [col.get_text() for col in players[0].find_all("th") if col.get_text()]
len(column_headers)
df.columns = column_headers
df.head()
#The header repeated itself in the data. This didn't reveal itself until the data type conversion step below
#but this fixes all occurrences of it.
rows_to_be_dropped = df.loc[df['Cap Hit'] == 'Cap %'].index
rows_to_be_kept = df.loc[df['Cap Hit'] != 'Cap %'].index
totlen = len(df)
df2a = df.drop(rows_to_be_kept)
df = df.drop(rows_to_be_dropped)
df2 = pd.Series(data=rows_to_be_dropped)
#Apply a regex to convert the 'Cap Hit' column from a string to a float.
# df['Cap Hit'] =(df['Cap Hit'].replace('[\$,)]', "", regex=True).replace( '[(]','-', regex=True ).astype(float))
# My fix
df['Cap.Hit'] = (df['Cap Hit'].replace('[\$,)]', "", regex=True).replace('[-,)]', "", regex=True).replace('\s\s.*', "", regex=True).astype(float))
df['Base.Salary'] = (df['Base Salary'].replace('[\$,)]', "", regex=True).replace('[-,)]', "", regex=True).astype(float))
df['Signing.Bonus'] = (df['Signing Bonus'].replace('[\$,)]', "", regex=True).replace('[-,)]', "", regex=True).astype(float))
df['Roster.Bonus'] = (df['Roster Bonus'].replace('[\$,)]', "", regex=True).replace('[-,)]', "", regex=True).astype(float))
df['Option.Bonus'] = (df['Option Bonus'].replace('[\$,)]', "", regex=True).replace('[-,)]', "", regex=True).astype(float))
df['Workout.Bonus'] = (df['Workout Bonus'].replace('[\$,)]', "", regex=True).replace('[-,)]', "", regex=True).astype(float))
df['Restruc.Bonus'] = (df['Restruc. Bonus'].replace('[\$,)]', "", regex=True).replace('[-,)]', "", regex=True).astype(float))
df['Misc'] = (df['Misc.'].replace('[\$,)]', "", regex=True).replace('[-,)]', "", regex=True).astype(float))
df['Dead.Cap'] = (df['Dead Cap'].replace('\(',"",regex=True).replace('\)',"",regex=True).replace('[\$,)]', "", regex=True).replace('[-,)]', "", regex=True).astype(float))
#Sanity check to make sure it worked.
df['Cap Hit'].sum()There are a few wonderful things about Beautiful Soup. But it is still faster and easier for me to do things in R. Here is some R code for the same task. The R table is a messy data structure but is easier to get.
library(stringr)
data.creator <- function(link) {
read_html(link) %>% html_nodes("table") %>% html_table(header=TRUE, fill=TRUE) -> res
names(res) <- c("Active","Draft","Inactive","Team1","Team2")
return(res)
}
team.names <- gsub("-", " ", team.names)
simpleCap <- function(x) {
s <- strsplit(x, " ")[[1]]
paste(toupper(substring(s, 1,1)), substring(s, 2),
sep="", collapse=" ")
}
team.names <- sapply(team.names, simpleCap)
NFL.scrape <- sapply(team.URL, function(x) {data.creator(x)})
names(NFL.scrape) <- team.names
# This is a hack but it works
Actives <- lapply(NFL.scrape, function(x){x$Active})
rep.res <- sapply(seq(1,32), function(x) {dim(Actives[[x]])[[1]]})
clean.me.2 <- function(data) {
data %>% str_remove_all("[\\t]") %>% str_split("\\n\\n\\n") %>% unlist() %>% matrix(data=., ncol=2, byrow=TRUE) -> dat
return(dat)
}
clean.me <- function(data) {
str_remove_all(data, "[\\t]")
}
clean.me.num <- function(data) {
str_remove_all(data, "[\\$,()\\-]")
}
Players <- lapply(Actives, function(x){ clean.me.2(x[,1])})
Last.Name <- unlist(lapply(Players, function(x) {x[,1]}))
Player.Name <- unlist(lapply(Players, function(x) {x[,2]}))
Team <- rep(names(Actives),rep.res)
Position <- unlist(lapply(Actives, function(x){ clean.me(x[,2])}))
Base.Salary <- unlist(lapply(Actives, function(x){ clean.me.num(x[,'Base Salary'])}))
Base.Salary <- as.numeric(Base.Salary)
Signing.Bonus <- unlist(lapply(Actives, function(x){ clean.me.num(x[,'Signing Bonus'])}))
Signing.Bonus <- as.numeric(Signing.Bonus)
Roster.Bonus <- unlist(lapply(Actives, function(x){ clean.me.num(x[,'Roster Bonus'])}))
Roster.Bonus <- as.numeric(Roster.Bonus)
Option.Bonus <- unlist(lapply(Actives, function(x){ clean.me.num(x[,'Option Bonus'])}))
Option.Bonus <- as.numeric(Option.Bonus)
Workout.Bonus <- unlist(lapply(Actives, function(x){ clean.me.num(x[,'Workout Bonus'])}))
Workout.Bonus <- as.numeric(Workout.Bonus)
Cap.Pct <- unlist(lapply(Actives, function(x){ x[,'Cap %']}))
Restruc.Bonus <- unlist(lapply(Actives, function(x){ clean.me.num(x[,'Restruc. Bonus'])}))
Restruc.Bonus <- as.numeric(Restruc.Bonus)
Dead.Cap <- unlist(lapply(Actives, function(x){ clean.me.num(x[,'Dead Cap'])}))
Dead.Cap <- as.numeric(Dead.Cap)
Misc.Cap <- unlist(lapply(Actives, function(x){ clean.me.num(x[,'Misc.'])}))
Misc.Cap <- as.numeric(Misc.Cap)
Cap.Hit <- unlist(lapply(Actives, function(x){ clean.me.num(x[,'Cap Hit'])}))
Cap.Hit <- str_replace_all(Cap.Hit, pattern="\\s\\s*", "")
NFL.Salary.Data <- data.frame(Player=Player.Name,
Last.Name = Last.Name,
Team=Team,
Position=Position,
Base.Salary=Base.Salary,
Signing.Bonus=Signing.Bonus,
Roster.Bonus=Roster.Bonus,
Option.Bonus=Option.Bonus,
Workout.Bonus=Workout.Bonus,
Cap.Hit=Cap.Hit,
Restruc.Bonus=Restruc.Bonus,
Dead.Cap=Dead.Cap,
Misc.Cap=Misc.Cap,
Cap.Pct=Cap.Pct)
save.image("~/NFL-Data.RData")Load up a local copy of the data for now.
load(url("https://github.com/robertwwalker/academic-mymod/raw/master/data/NFL-Data.RData"))Summaries
library(tidyverse)
library(skimr)
skim(NFL.Salary.Data)| Name | NFL.Salary.Data |
| Number of rows | 2239 |
| Number of columns | 14 |
| _______________________ | |
| Column type frequency: | |
| factor | 5 |
| numeric | 9 |
| ________________________ | |
| Group variables | None |
Variable type: factor
| skim_variable | n_missing | complete_rate | ordered | n_unique | top_counts |
|---|---|---|---|---|---|
| Player | 0 | 1 | FALSE | 2226 | Aus: 2, Bra: 2, Bra: 2, Chr: 2 |
| Last.Name | 0 | 1 | FALSE | 1489 | Jon: 41, Wil: 39, Smi: 31, Joh: 30 |
| Team | 0 | 1 | FALSE | 32 | New: 86, Ind: 78, New: 78, Cle: 77 |
| Position | 0 | 1 | FALSE | 22 | WR: 289, CB: 242, DE: 179, OLB: 171 |
| Cap.Hit | 0 | 1 | FALSE | 1043 | 480: 279, 555: 230, 630: 185, 705: 66 |
Variable type: numeric
| skim_variable | n_missing | complete_rate | mean | sd | p0 | p25 | p50 | p75 | p100 | hist |
|---|---|---|---|---|---|---|---|---|---|---|
| Base.Salary | 0 | 1 | 1702378.82 | 2559999.20 | 0 | 555000.00 | 700000.00 | 1500000.00 | 22500000.00 | ▇▁▁▁▁ |
| Signing.Bonus | 0 | 1 | 449440.82 | 961034.55 | 0 | 0.00 | 3333.00 | 397413.50 | 10500000.00 | ▇▁▁▁▁ |
| Roster.Bonus | 0 | 1 | 206966.64 | 1021892.52 | 0 | 0.00 | 0.00 | 0.00 | 28800000.00 | ▇▁▁▁▁ |
| Option.Bonus | 0 | 1 | 13272.29 | 168050.78 | 0 | 0.00 | 0.00 | 0.00 | 4750000.00 | ▇▁▁▁▁ |
| Workout.Bonus | 0 | 1 | 20166.59 | 76589.41 | 0 | 0.00 | 0.00 | 0.00 | 1335000.00 | ▇▁▁▁▁ |
| Restruc.Bonus | 0 | 1 | 44915.31 | 341687.19 | 0 | 0.00 | 0.00 | 0.00 | 5561666.00 | ▇▁▁▁▁ |
| Dead.Cap | 0 | 1 | 2237274.35 | 5646281.55 | 0 | 0.00 | 50178.00 | 1330354.50 | 82500000.00 | ▇▁▁▁▁ |
| Misc.Cap | 0 | 1 | 9149.17 | 81182.62 | 0 | 0.00 | 0.00 | 0.00 | 2085000.00 | ▇▁▁▁▁ |
| Cap.Pct | 0 | 1 | 1.36 | 2.05 | 0 | 0.31 | 0.41 | 1.42 | 18.02 | ▇▁▁▁▁ |
NFL.Salary.Data %>% group_by(Team) %>% summarise(Total.Base.Salary=sum(Base.Salary))## # A tibble: 32 x 2
## Team Total.Base.Salary
## * <fct> <dbl>
## 1 Arizona Cardinals 105629569
## 2 Atlanta Falcons 132367353
## 3 Baltimore Ravens 111906351
## 4 Buffalo Bills 94577460
## 5 Carolina Panthers 110158355
## 6 Chicago Bears 85128180
## 7 Cincinnati Bengals 134855807
## 8 Cleveland Browns 122139767
## 9 Dallas Cowboys 128347113
## 10 Denver Broncos 140672444
## # … with 22 more rowsNFL.Salary.Data %>% group_by(Position) %>% skim(Base.Salary)| Name | Piped data |
| Number of rows | 2239 |
| Number of columns | 14 |
| _______________________ | |
| Column type frequency: | |
| numeric | 1 |
| ________________________ | |
| Group variables | Position |
Variable type: numeric
| skim_variable | Position | n_missing | complete_rate | mean | sd | p0 | p25 | p50 | p75 | p100 | hist |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Base.Salary | C | 0 | 1 | 1964379.0 | 2173761.0 | 0 | 630000.0 | 862290.5 | 2693750 | 9000000 | ▇▂▁▁▁ |
| Base.Salary | CB | 0 | 1 | 1594781.4 | 2433196.2 | 0 | 555000.0 | 630000.0 | 1329725 | 13500000 | ▇▁▁▁▁ |
| Base.Salary | DE | 0 | 1 | 2007139.1 | 3065728.5 | 0 | 555000.0 | 790000.0 | 1812276 | 17143000 | ▇▁▁▁▁ |
| Base.Salary | DT | 0 | 1 | 2014004.0 | 3128524.2 | 0 | 555000.0 | 630000.0 | 1760393 | 16985000 | ▇▁▁▁▁ |
| Base.Salary | FB | 0 | 1 | 815000.0 | 560564.0 | 0 | 555000.0 | 667500.0 | 837500 | 2750000 | ▂▇▁▁▁ |
| Base.Salary | FS | 0 | 1 | 2641985.1 | 2783070.4 | 0 | 762911.0 | 1426150.0 | 3250000 | 11287000 | ▇▁▁▁▁ |
| Base.Salary | G | 0 | 1 | 1704599.2 | 2115607.1 | 0 | 555000.0 | 790000.0 | 1880750 | 10000000 | ▇▁▁▁▁ |
| Base.Salary | ILB | 0 | 1 | 1378939.2 | 1901654.3 | 0 | 555000.0 | 705000.0 | 1049127 | 10000000 | ▇▁▁▁▁ |
| Base.Salary | K | 0 | 1 | 1383498.1 | 946083.5 | 480000 | 555000.0 | 899464.0 | 2037500 | 3400000 | ▇▂▂▂▂ |
| Base.Salary | LB | 0 | 1 | 616500.0 | NA | 616500 | 616500.0 | 616500.0 | 616500 | 616500 | ▁▁▇▁▁ |
| Base.Salary | LS | 0 | 1 | 761617.7 | 201707.6 | 480000 | 573750.0 | 790000.0 | 915000 | 1100000 | ▇▆▅▅▆ |
| Base.Salary | LT | 0 | 1 | 4587732.8 | 4142986.8 | 0 | 961056.2 | 2310342.0 | 8825000 | 12496000 | ▇▁▂▂▂ |
| Base.Salary | OLB | 0 | 1 | 1938283.6 | 2869077.8 | 0 | 555000.0 | 705000.0 | 1639242 | 14750000 | ▇▁▁▁▁ |
| Base.Salary | P | 0 | 1 | 1242027.0 | 803853.9 | 480000 | 555000.0 | 1000000.0 | 1500000 | 3000000 | ▇▃▁▁▂ |
| Base.Salary | QB | 0 | 1 | 3408382.2 | 5078200.9 | 0 | 592500.0 | 831832.0 | 3242341 | 22500000 | ▇▁▁▁▁ |
| Base.Salary | RB | 0 | 1 | 1088425.3 | 1459116.9 | 0 | 555000.0 | 630000.0 | 1000000 | 14544000 | ▇▁▁▁▁ |
| Base.Salary | RT | 0 | 1 | 2314986.2 | 1962841.7 | 0 | 768750.0 | 1897621.0 | 3918750 | 9341000 | ▇▅▃▁▁ |
| Base.Salary | S | 0 | 1 | 576320.5 | 123126.2 | 0 | 480000.0 | 555000.0 | 630000 | 1037723 | ▁▁▇▆▁ |
| Base.Salary | SS | 0 | 1 | 1566535.6 | 1521405.5 | 0 | 630000.0 | 875000.0 | 1750000 | 6800000 | ▇▂▂▁▁ |
| Base.Salary | T | 0 | 1 | 587082.0 | 222252.3 | 480000 | 480000.0 | 555000.0 | 630000 | 2312212 | ▇▁▁▁▁ |
| Base.Salary | TE | 0 | 1 | 1301806.2 | 1570488.6 | 480000 | 555000.0 | 630000.0 | 1048771 | 8250000 | ▇▁▁▁▁ |
| Base.Salary | WR | 0 | 1 | 1624579.2 | 2486576.1 | 0 | 555000.0 | 630000.0 | 1200000 | 15982000 | ▇▁▁▁▁ |
Now I have my salary data.
gplots::plotmeans(Base.Salary~Position, data=NFL.Salary.Data, n.label=FALSE, cex=0.6)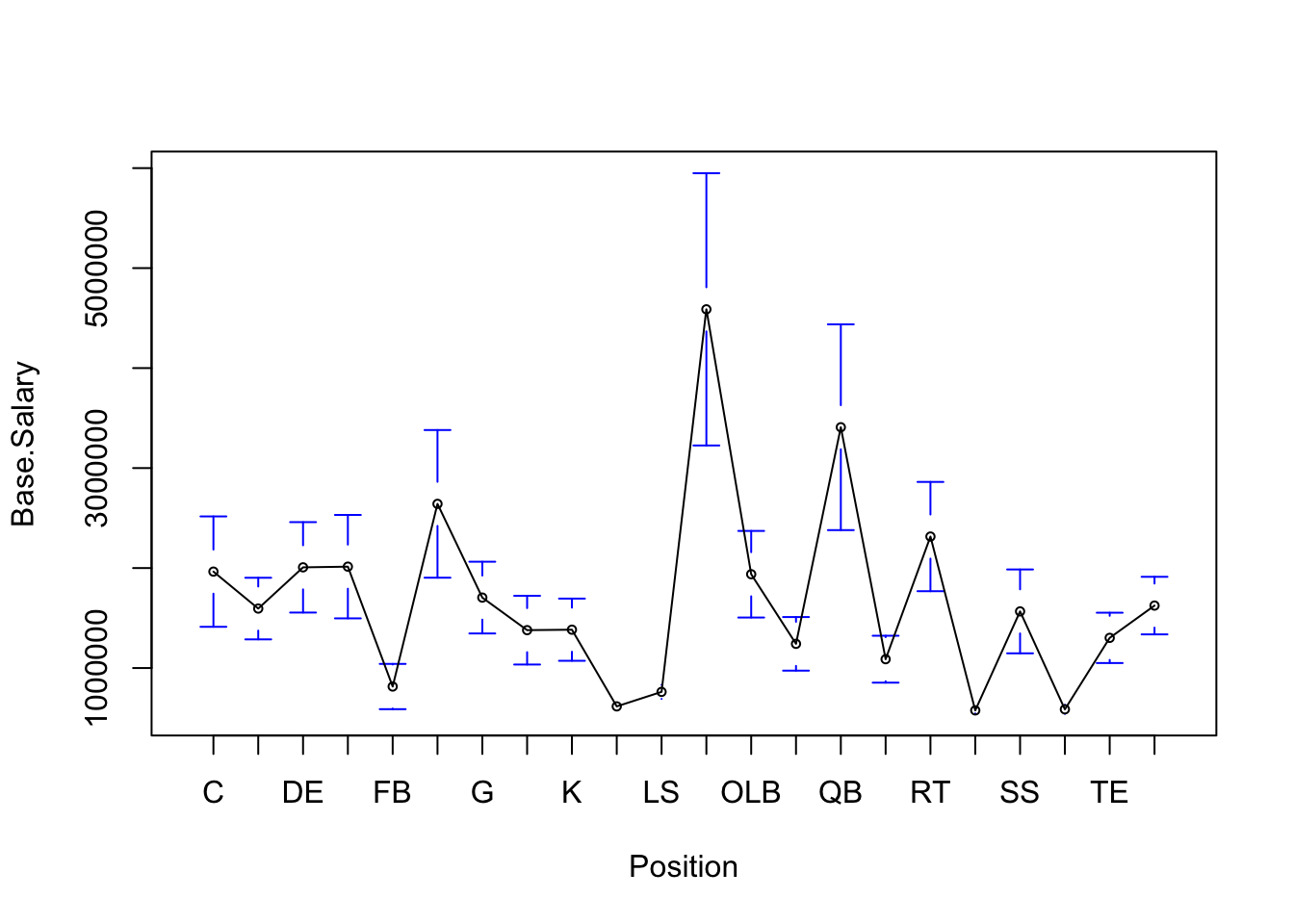
boxplot(Base.Salary~Position, data=NFL.Salary.Data)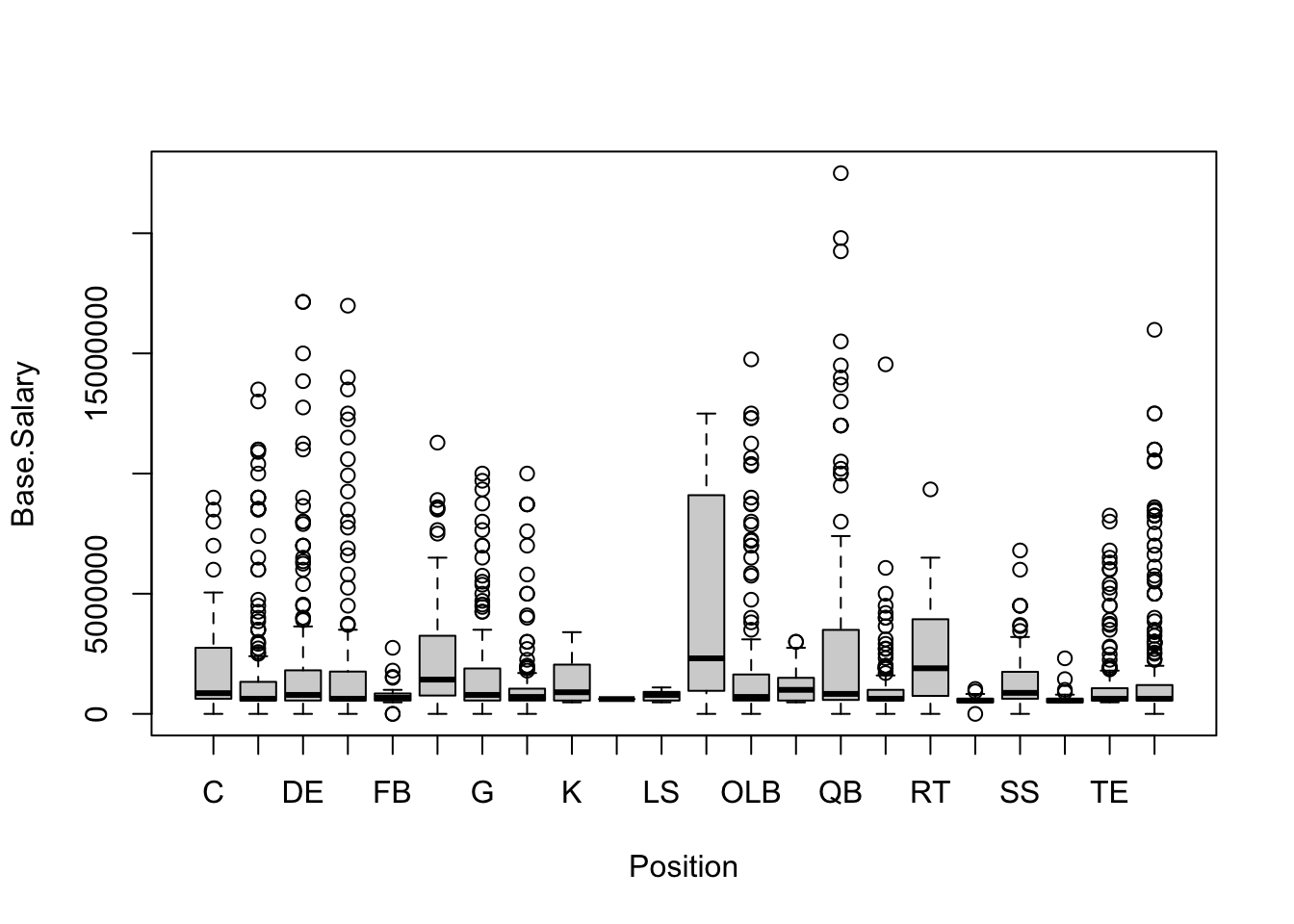
Combining and Categorizing Data
NFL.Salary.Data$Pos.Char <- NFL.Salary.Data$SideOfBall <- NFL.SubTeam <- as.character(NFL.Salary.Data$Position)
O.Line <- c("LT","RT","C","G","T")
D.Line <- c("DT","DE")
LineBackers <- c("LB","ILB","OLB")
Safeties <- c("S","SS","FS")
CBs <- c("CB")
Special.Teams <- c("K","P","LS")
RBs <- c("RB","FB")
TEs <- c("TE")
WRs <- c("WR")
QBs <- c("QB")
Offense <- c(QBs,RBs,WRs,TEs,O.Line)
Defense <- c(D.Line,LineBackers,Safeties,CBs)
NFL.Salary.Data$SideOfBall[NFL.Salary.Data$Pos.Char %in% Offense] <- "Offense"
NFL.Salary.Data$SideOfBall[NFL.Salary.Data$Pos.Char %in% Special.Teams] <- "Special Teams"
NFL.Salary.Data$SideOfBall[NFL.Salary.Data$Pos.Char %in% Defense] <- "Defense"
NFL.Salary.Data$SubTeam[NFL.Salary.Data$Pos.Char %in% Special.Teams] <- "Special Teams"
NFL.Salary.Data$SubTeam[NFL.Salary.Data$Pos.Char %in% QBs] <- "Quarterbacks"
NFL.Salary.Data$SubTeam[NFL.Salary.Data$Pos.Char %in% RBs] <- "Running Backs"
NFL.Salary.Data$SubTeam[NFL.Salary.Data$Pos.Char %in% TEs] <- "Tight Ends"
NFL.Salary.Data$SubTeam[NFL.Salary.Data$Pos.Char %in% WRs] <- "Wide Receivers"
NFL.Salary.Data$SubTeam[NFL.Salary.Data$Pos.Char %in% O.Line] <- "Offensive Line"
NFL.Salary.Data$SubTeam[NFL.Salary.Data$Pos.Char %in% LineBackers] <- "Linebackers"
NFL.Salary.Data$SubTeam[NFL.Salary.Data$Pos.Char %in% CBs] <- "Cornerbacks"
NFL.Salary.Data$SubTeam[NFL.Salary.Data$Pos.Char %in% D.Line] <- "Defensive Line"
NFL.Salary.Data$SubTeam[NFL.Salary.Data$Pos.Char %in% Safeties] <- "Safeties"That gives some positional details to the data also.