tidyTuesday: coffee chains
The tidyTuesday for this week is coffee chain locations
For this week:
1. The basic link to the #tidyTuesday shows an original article for Week 6.
First, let’s import the data; it is a single Excel spreadsheet. The page notes that starbucks, Tim Horton, and Dunkin Donuts have raw data available.
library(readxl)
library(tidyverse)## ── Attaching packages ─────────────────────────────────────── tidyverse 1.3.0 ──## ✓ ggplot2 3.3.3 ✓ purrr 0.3.4
## ✓ tibble 3.0.6 ✓ dplyr 1.0.4
## ✓ tidyr 1.1.2 ✓ stringr 1.4.0
## ✓ readr 1.4.0 ✓ forcats 0.5.1## ── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
## x dplyr::filter() masks stats::filter()
## x dplyr::lag() masks stats::lag()library(janitor)##
## Attaching package: 'janitor'## The following objects are masked from 'package:stats':
##
## chisq.test, fisher.testlibrary(geofacet)
library(ggbeeswarm)
library(ggrepel)
# A great function appears below that I grabbed from Stack Overflow a while back.....
# URL functionality with read_excel is tricky so I turned them in to rds
read_excel_allsheets <- function(filename, tibble = TRUE) {
sheets <- readxl::excel_sheets(filename)
x <- lapply(sheets, function(X) readxl::read_excel(filename, sheet = X))
if(!tibble) x <- lapply(x, as.data.frame)
names(x) <- sheets
x
}
download.file("https://github.com/rfordatascience/tidytuesday/raw/master/data/2018/2018-05-07/week6_coffee_chains.xlsx", "coffee.xlsx")
coffee.xl <- read_excel_allsheets("coffee.xlsx")
Starbucks <- readRDS(url("https://github.com/robertwwalker/academic-mymod/raw/master/data/week6SB.rds"))
Dunkin.Donuts <- readRDS(url("https://github.com/robertwwalker/academic-mymod/raw/master/data/week6DD.rds"))
Tim.Hortons <- readRDS(url("https://github.com/robertwwalker/academic-mymod/raw/master/data/week6TH.rds"))What do the data look like?
library(skimr)
skim(Starbucks)| Name | Starbucks |
| Number of rows | 25600 |
| Number of columns | 13 |
| _______________________ | |
| Column type frequency: | |
| character | 11 |
| numeric | 2 |
| ________________________ | |
| Group variables | None |
Variable type: character
| skim_variable | n_missing | complete_rate | min | max | empty | n_unique | whitespace |
|---|---|---|---|---|---|---|---|
| Brand | 0 | 1.00 | 7 | 21 | 0 | 4 | 0 |
| Store Number | 0 | 1.00 | 5 | 12 | 0 | 25599 | 0 |
| Store Name | 0 | 1.00 | 2 | 60 | 0 | 25364 | 0 |
| Ownership Type | 0 | 1.00 | 8 | 13 | 0 | 4 | 0 |
| Street Address | 2 | 1.00 | 1 | 234 | 0 | 25353 | 0 |
| City | 14 | 1.00 | 2 | 29 | 0 | 5470 | 0 |
| State/Province | 0 | 1.00 | 1 | 3 | 0 | 338 | 0 |
| Country | 0 | 1.00 | 2 | 2 | 0 | 73 | 0 |
| Postcode | 1521 | 0.94 | 1 | 9 | 0 | 18888 | 0 |
| Phone Number | 6861 | 0.73 | 1 | 18 | 0 | 18559 | 0 |
| Timezone | 0 | 1.00 | 18 | 30 | 0 | 101 | 0 |
Variable type: numeric
| skim_variable | n_missing | complete_rate | mean | sd | p0 | p25 | p50 | p75 | p100 | hist |
|---|---|---|---|---|---|---|---|---|---|---|
| Longitude | 1 | 1 | -27.87 | 96.84 | -159.46 | -104.66 | -79.35 | 100.63 | 176.92 | ▇▇▂▂▅ |
| Latitude | 1 | 1 | 34.79 | 13.34 | -46.41 | 31.24 | 36.75 | 41.57 | 64.85 | ▁▁▁▇▂ |
skim(Dunkin.Donuts)| Name | Dunkin.Donuts |
| Number of rows | 4898 |
| Number of columns | 22 |
| _______________________ | |
| Column type frequency: | |
| character | 13 |
| numeric | 9 |
| ________________________ | |
| Group variables | None |
Variable type: character
| skim_variable | n_missing | complete_rate | min | max | empty | n_unique | whitespace |
|---|---|---|---|---|---|---|---|
| biz_name | 0 | 1.00 | 8 | 38 | 0 | 33 | 0 |
| e_address | 0 | 1.00 | 6 | 61 | 0 | 4864 | 0 |
| e_city | 0 | 1.00 | 2 | 27 | 0 | 1770 | 0 |
| e_state | 0 | 1.00 | 2 | 2 | 0 | 41 | 0 |
| e_zip_full | 0 | 1.00 | 10 | 10 | 0 | 545 | 0 |
| e_country | 0 | 1.00 | 3 | 3 | 0 | 1 | 0 |
| loc_county | 0 | 1.00 | 3 | 21 | 0 | 395 | 0 |
| loc_PMSA | 0 | 1.00 | 2 | 4 | 0 | 53 | 0 |
| loc_TZ | 0 | 1.00 | 3 | 5 | 0 | 5 | 0 |
| loc_DST | 0 | 1.00 | 1 | 1 | 0 | 3 | 0 |
| web_url | 0 | 1.00 | 20 | 175 | 0 | 22 | 0 |
| biz_info | 4091 | 0.16 | 14 | 18 | 0 | 709 | 0 |
| biz_phone | 0 | 1.00 | 14 | 14 | 0 | 4562 | 0 |
Variable type: numeric
| skim_variable | n_missing | complete_rate | mean | sd | p0 | p25 | p50 | p75 | p100 | hist |
|---|---|---|---|---|---|---|---|---|---|---|
| id | 0 | 1 | 2459.46 | 1420.28 | 1.00 | 1231.25 | 2458.50 | 3686.75 | 4920.00 | ▇▇▇▇▇ |
| e_postal | 0 | 1 | 21528.34 | 20311.57 | 1001.00 | 6080.00 | 13334.50 | 32810.75 | 98112.00 | ▇▃▁▁▁ |
| loc_area_code | 0 | 1 | 590.09 | 229.26 | 201.00 | 401.00 | 610.00 | 781.00 | 989.00 | ▇▅▇▇▆ |
| loc_FIPS | 0 | 1 | 27911.17 | 12470.14 | 1069.00 | 17031.00 | 26125.00 | 36111.00 | 55111.00 | ▂▅▆▇▂ |
| loc_MSA | 0 | 1 | 4284.65 | 2849.57 | 160.00 | 1520.00 | 3800.00 | 6880.00 | 9320.00 | ▇▃▂▆▅ |
| loc_LAT_centroid | 0 | 1 | 39.62 | 4.33 | 21.42 | 39.39 | 41.22 | 42.11 | 47.63 | ▁▁▁▇▂ |
| loc_LAT_poly | 0 | 1 | 39.62 | 4.32 | 21.39 | 39.38 | 41.20 | 42.09 | 47.64 | ▁▁▁▇▂ |
| loc_LONG_centroid | 0 | 1 | -77.55 | 7.31 | -157.93 | -81.44 | -75.08 | -72.66 | -67.23 | ▁▁▁▁▇ |
| loc_LONG_poly | 0 | 1 | -77.55 | 7.31 | -157.96 | -81.44 | -75.08 | -72.66 | -67.28 | ▁▁▁▁▇ |
skim(Tim.Hortons)| Name | Tim.Hortons |
| Number of rows | 4955 |
| Number of columns | 6 |
| _______________________ | |
| Column type frequency: | |
| character | 6 |
| ________________________ | |
| Group variables | None |
Variable type: character
| skim_variable | n_missing | complete_rate | min | max | empty | n_unique | whitespace |
|---|---|---|---|---|---|---|---|
| country | 0 | 1 | 2 | 2 | 0 | 2 | 0 |
| address | 0 | 1 | 6 | 51 | 0 | 4803 | 0 |
| city | 0 | 1 | 3 | 38 | 0 | 1206 | 0 |
| postal_code | 0 | 1 | 4 | 7 | 0 | 4328 | 0 |
| state | 0 | 1 | 2 | 2 | 0 | 27 | 0 |
| store_name | 0 | 1 | 2 | 63 | 0 | 3167 | 0 |
A basic plot of the global Starbucks data.
library(ggmap)## Google's Terms of Service: https://cloud.google.com/maps-platform/terms/.## Please cite ggmap if you use it! See citation("ggmap") for details.mapWorld <- borders("world", colour="gray50", fill="gray50") # create a layer of borders
mp <- ggplot() + mapWorld
mp <- mp + geom_point(aes(x=Starbucks$Longitude, y=Starbucks$Latitude) ,color="dark green", size=0.5) + xlab("") + ylab("")
mp <- mp + geom_point(aes(x=Dunkin.Donuts$loc_LONG_centroid, y=Dunkin.Donuts$loc_LAT_centroid) ,color="orange", size=0.5) + xlab("") + ylab("")
mp## Warning: Removed 1 rows containing missing values (geom_point).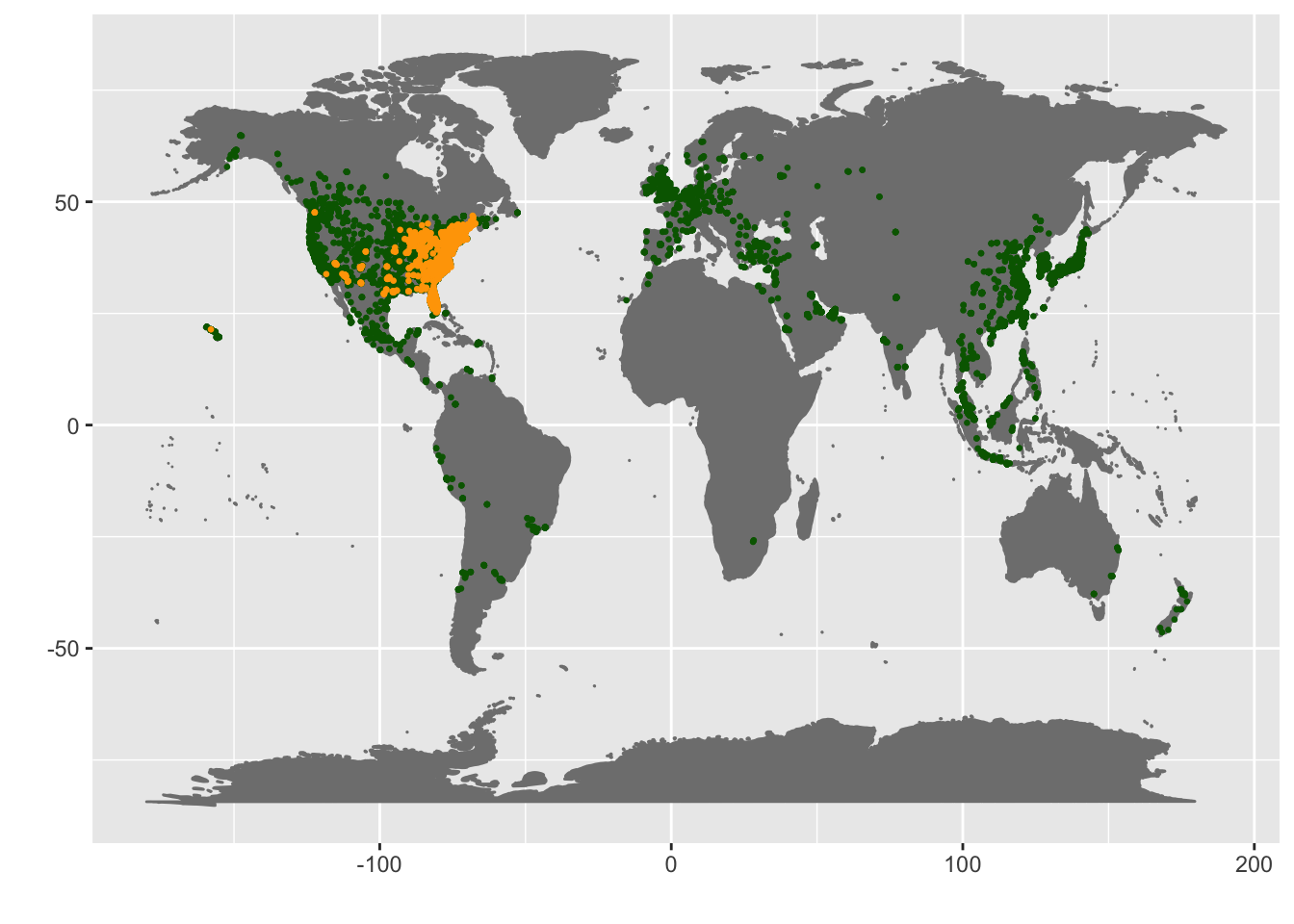
Starbucks and Dunkin
Google Maps interface changed and I have not updated this part. Shame.